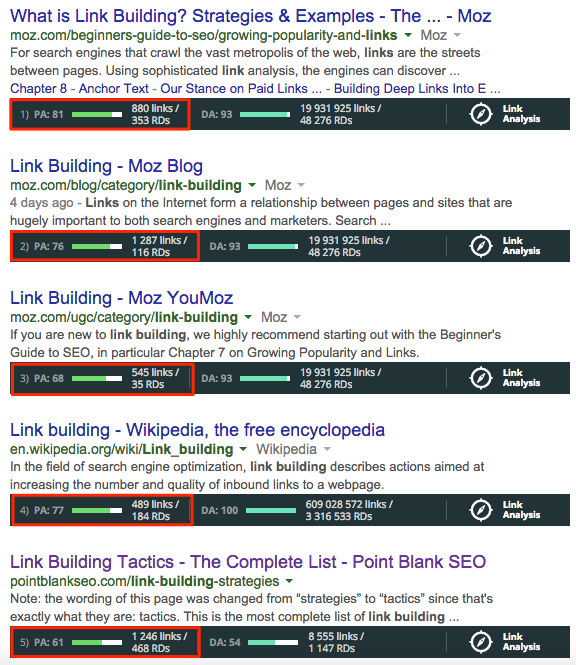
„Sémantický web se má stát novým evolučním stupněm stávajícího webu. Jedná se o web, kde jsou informace strukturovány a uloženy podle standardizovaných pravidel, což usnadňuje jejich vyhledání a zpracování. Staví zejména na Resource Description Framework (RDF) a Ontology Web Language (OWL).“
Tak zní definice sémantického webu na české Wikipedii. Dovolím si krátký a rychlý exkurz do historie a jak se k němu vůbec došlo.
V roce 1989 Sir Timothy „Tim“ John Berners-Lee přišel s nápadem pro organizaci a propojení informací napříč jednotlivými vědeckými pracovišti. A tak se postupně zrodil HTTP, World Wide Web, HTML a první prohlížeč.
Tima prostě štvalo, že se nedaly rozumně sdílet dokumenty napříč lidmi v CERNu a ideálně po celém světě. Každý měl svůj vlastní formát a neexistoval žádný standard. Vznikl tak koncept hypertextu, který se rozšířil a díky kterému si mimo jiné čtete tento článek.
V hypertextu jde o to, že každý dokument (článek, obrázek, PDF, …) má vlastní HTTP adresu. Díky tomu si mohu dokument stáhnout přes prohlížeč ve standardizovném formátu.
Dokumenty samy o sobě nemají explicitní význam. Nedokážete z nich strojově vyčíst, jaké informace obsahují, jak jsou propojeny s dalšími dokumenty apod. Jen víte, že dokument A odkazuje na dokument B. Takže asi budou nějak příbuzné. A nebo si tam prostě někdo zaplatil odkaz 🙂
To ale bylo Berners-Leeovi málo a tak v roce 2006 přišel s konceptem Linked Data. Ten staví na principu, že každý dokument má vlastní HTTP adresu a data jsou uložena ve strukturované formě a dají se mezi sebou propojovat. A hlavně nad nimi pokládat sémantické dotazy. Ty mohou pokládat jak lidé, tak i stroje.
Koukněte na tento TED talk s Timem.
Jako příklad si vezmeme mě — já Martin Šimko jsem se narodil na Náměstí sovětských hrdinů v Brně (což je historický název současného Obilního trhu).
Díky sémantice se teď mohu zanořovat hlouběji a zjistit, že Brno je druhé největší město v Česku, má 377 440 obyvatel apod. Nebo jít do šířky — zjistit, kdo se dále v Brně narodil.
První reálná aplikace Linked Data byla DBpedia, která extrahuje strojově čitelná data a vazby mezi nimi z Wikipedie.
K ní se postupně přidávaly další iniciativy jako Geo Names apod. Stav k roku 2014 vypadal takto:

Jak se dají využít Linked Data
Konec teorie. Jak ale Linked Data využít? Pokud budou data zveřejněna v otevřené a syrové podobně, můžeme poté pokládat dotazy typu:
Které proteiny jsou v signální transdukci a jsou příbuzné pyramidovým neuronům?
Nebo možná něco pochopitelnějšího:
Které obchody, kde se dá platit kartou, jsou otevřeny 1. a 8. května v Brno-Střed?
To už by se mohlo hodit v běžném životě, ne? Sami si určitě doplníte další dotazy, které by se daly pokládat.
A co s tím má společného SEO a vyhledávače?
Možná si říkáte, že to je dost odtržené od reality. Ano. Zatím. Ale změna se blíží.
Google chce ze sémantického webu a Linked Data taky něco mít. A tak společně s Microsoftem, Yahoo a Yandex dal dohromady v roce 2011 Schema.org.
To už pravděpodobně znáte, že? Jde o koncept, který se snaží definovat a vytvářet standard pro strukturovaná data.
Strukturovaná data pomáhají označovat informace v dokumentech na webu tak, aby byla strojově čitelná a zpracovatelná. Takže taková Linked Data.
Není asi náhoda, že roku 2012 přišel Google se svým Knowledge Graphem.
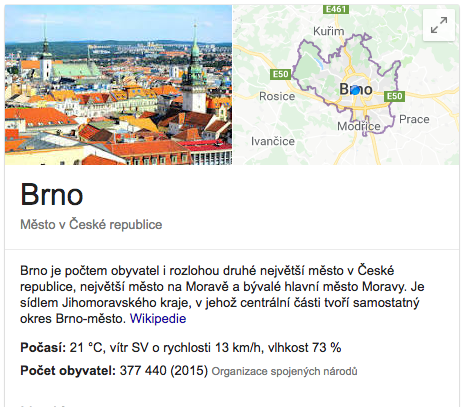
No a to že dnes máme mimo Knowledge panelu Featured snippety, živé výsledky sportovních zápasů přímo v SERPu atd. atd. je jen další vývoj.
A přijde toho víc. Fakt.
Strukturovaná data a vyhledávače
Nasazením strukturovaných dat na svůj web pomáháme vyhledávačům pochopit náš obsah a dále s ním pracovat.
Strukturovaná data tak působí jako trénovací množina. Díky tomu vyhledávače následně dokáží zpracovávat informace i bez strukturovaných dat. Alespoň do určité míry.
Takže teď už máme teoretický základ a víme, k čemu to vyhledávače dokáží používat.
Proč bych měl ale strukturovaná data nasazovat na svůj web?
Ještě nám chybí odpověď na otázku proč. Proč já? Proč strukturovaná data?
Aby Google motivoval webmastery strukturovaná data nasazovat, dává nám něco na oplátku. A sice rozšířené výsledky vyhledávání ~ rich snippety.
Reálné ukázky si můžete prohlédnout níže.
[ngg_images source=“galleries“ container_ids=“11″ display_type=“photocrati-nextgen_basic_thumbnails“ override_thumbnail_settings=“0″ thumbnail_width=“100″ thumbnail_height=“75″ thumbnail_crop=“1″ images_per_page=“20″ number_of_columns=“0″ ajax_pagination=“0″ show_all_in_lightbox=“0″ use_imagebrowser_effect=“0″ show_slideshow_link=“1″ slideshow_link_text=“[Show as slideshow]“ order_by=“sortorder“ order_direction=“ASC“ returns=“included“ maximum_entity_count=“500″]
No a všechny tyto rozšířené výsledky vyhledávání vám dokáží pěkně navýšit CTR ze SERPu a přivést větší návštěvnost. Ověřeno.
Strukturovaná data jsou navíc základním kamenem v entitním SEO. Což jsou mimochodem právě Linked Data.
Nasazujeme strukturovaná data
Takže už je jasné, že strukturovaná data nám mohou pomoci navýšit CTR (nikoli přímo pozice) ze SERPu.
Důležité je ale připomenout, že:
Strukturovaná data řešte, až máte odladěny základní věci v SEO.
Pokud máte web plný duplicit, problémy s indexací, nekvalitní obsah, chybějící vstupní stránky apod., strukturovaná data nejsou rozhodně vaší prioritou.
Jaká strukturovaná data nasazovat
Google má v nápovědě vybrané datové typy, které aktuálně podporuje, zpracovává a je z toho reálný výstup i pro majitele webu v SERPu.
To ovšem neznamená, že těmito datovými typy byste měli skončit. Existuje totiž několikanásobek dalších typů, které Google zatím oficiálně nedoporučuje.
V době psaní článku Google ve své nápovědě doporučuje cca 49 datových typů. Na Schema.org jich je cca 774.
To se ale nerovná, že co nedoporučuje, ignoruje. Gary Illyes z Googlu se totiž nechal slyšet:
“It will help us understand your pages better, and indirectly, it leads to better ranks in some sense, because we can rank easier.”
A také:
“And do not just think about the structured data that we documented on developers.Google.com. Think about any schema.org schema that you could use on your page.”
Fráze jako „understand pages better“ a „rank easier“ jsou pro SEO konzultanty a weby fajn, že?
Hodně podceňované datové typy strukturovaných dat jsou podle mě následující:
- sameAs — pomáhá vytvářet vztahy mezi jednotlivými objekty/entitami. Můžete ze stránky o autorovi knih odkazovat na jeho sociální sítě, oficiální web, Wiki stránku apod. Tím zasadíte vše do kontextu. Odkazujte i na cizojazyčné stránky. Objekty/entity totiž nejsou přímo závislé na jazyku.
- Dataset — pokud na webu zveřejňujete nějaké datasety, tak určitě nepřehlédněte tento datový typ. Opět nově podporovaný Googlem. Zatím můžeme hádat, co s tím bude vymýšlet. Ale podle mě půjde cestou, kterou si vysnil Tim Bernerns-Lee — otevřená Linked Data.
Možnosti nasazení
Zjednodušeně řečeno, do jednotlivých stránek webu musíte dostat kus kódu, který označuje informace a dává jim sémantiku. Ty potom dokáží stroje (Google, Seznam a další roboti) strojově zpracovat a „pochopit“.
Aktuálně je několik možností, jak strukturovaná data na web dostat:
- JSON-LD — kus JavaScriptu, který přidáte do stránky. Nejjednodušší a Googlem doporučované řešení.
- Mikrodata — strukturovaná data vkládáte přímo do HTML kódu.
- RDFa — strukturovaná data vkládáte přímo do HTML kódu.
- Search Console — můžete si přímo v rozhraní Search Console naklikat, které informace chcete označit. Většinou to je ale problém, takže tuto možnost doporučuji až jako krajní.
Návod nasazení krok za krokem
Před pár lety jsem napsal článek pro TyInternety.cz s poměrně podrobným návodem, který je pořád platný. Takže zde dám pouze odkaz.
Můžete také kouknout na návod od Googlu na Codelabs, jak strukturovaná data nasadit.
Jde to i přes Google Tag Manager
Strukturovaná data lze nasadit i přes Google Tag Manager. Někdy je to rychlejší a levnější cesta. Hlavně když máte vytížené programátory. A kdo to má dnes jinak, že…
Návody sepsali jiní, takže jen odkazy:
Jak zkontrolovat, že mám strukturovaná data správně nasazená
Když už si dáte tu práci, že správně strukturovaná data vyberete a donutíte programátory, aby vám je nasadili, tak je potřeba je ještě pořádně zkontrolovat. Není nic smutnějšího, než mít na webu X řádků mrtvého kódu.
Takže jak na to?
Nástroj na testování strukturovaných dat od Googlu
Google nabízí oficiální nástroj, který vám s kontrolou pomůže. Vložit můžete jak fragment kódu, tak URL, kde máte strukturovaná data nasazená.
Search Console
Pod záložkou Vzhled vyhledávání > Strukturovaná data najdete přehled nasazených dat na vašem webu. Data vycházejí z toho, které stránky už Google prošel. Takže po nasazení je potřeba chvíli počkat.
Já tento report používám pro pravidelnou kontrolu, zda se nic nepokazilo. Ne pro kontrolu hned po nasazení.
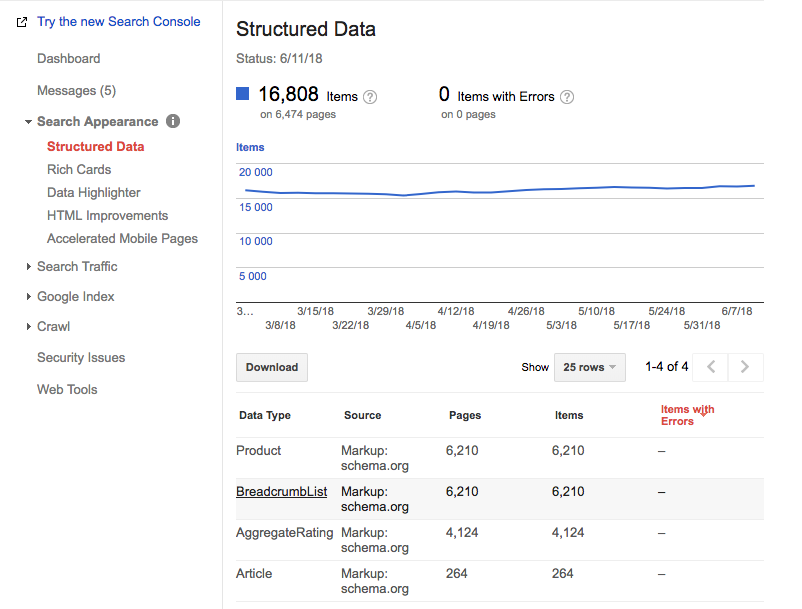
Marketing Miner
Český Marketing Miner vám také pomůže s jednorázovou kontrolou strukturovaných dat.
Nástroj můžete použít i pro stalkování konkurentů 😉
Jaká strukturovaná data jsou nejčastěji používaná?
Všechny datové typy jsou prezentované na webu Schema.org. Je jich poměrně dost (k datu psaní článku cca 774) a stále přibývají. Google jich aktuálně doporučuje cca 49.
A mě zajímalo, která strukturovaná data se používají nejčastěji. A jestli se to prolíná s tím, co tlačí Google. No a výsledky vypadají následovně:
[ngg_images source=“galleries“ container_ids=“10″ display_type=“photocrati-nextgen_basic_imagebrowser“ ajax_pagination=“0″ order_by=“sortorder“ order_direction=“ASC“ returns=“included“ maximum_entity_count=“500″]
Jde tedy krásně vidět, že spolu koreluje, která data jsou používaná a která doporučuje Google.
Náhoda? Nemyslím si…
Kde jsem vzal data
Data, která prezentuji výše jsem vyscrapoval přímo ze Schema.org. U jednotlivých datových typů jsou uvedeny informace, kolik webů je používá.
Pomiňme, že čísla jsou určitě pro zjednodušení zaokrouhlená a nemusí být 100% aktuální. Jde nám o trend. A ten je jasný.
Zdrojový dokument s daty najdete zde.
Kde se inspirovat
Vždy je dobré podívat se na weby, které si procesem nasazení strukturovaných dat už prošly. Dejte si jednotlivé stránky do validátoru nebo Marketing Mineru. Třeba tam objevíte i nové datové typy, které se vám budou hodit a předtím jste je ani nezvažovali.
Přidávám pár webů pro inspiraci.
Obsahové weby
E-commerce
Další informace nejdete v mé přednášce ze SEO restartu 2018: